|
- レポート課題として出題した、制約伝播処理 − その具体的な適用例としての線画のラベリングについての資料です。
- プリントアウト、ダウンロード等は自由ですが、 著作権は平賀に属しますので無断配布等はしないでください。
- 目次 授業のトップページに戻る
線画の情報を表現する方法はいろいろある:画像認識という観点からは最後の画像データ入力が本筋だが、処理は格段に複雑になる。
- 辺・頂点の接続情報を記号的(定性的)に与える。
- 線画の画面上で、頂点の(平面)座標、頂点の同士の接続情報(=辺)を与える。
各頂点の種類(L, A, Y, T 型のいずれか)を割り出す必要がある。
- 線画が表す立体の頂点の(空間)座標、接続情報を与える。
この場合、どの位置から見るかという視点の情報も合わせて指定する必要があり、
そこから図形が「一般の位置」(*) として見えるものでなければならない。
その上では、3次元情報を2次元画面情報に投影することにより、前項に戻る。
*「一般の位置」:視点の微小な移動により、情景が定性的に変化しないような配置。
例えば2つの辺が重なっているような視点は、 わずかなズレでも2つの辺が別々になるので一般の位置ではない。
- 画像データそのものを与える。
辺や頂点の画像からの抽出が必要となる。
そこで以下では最初の「頂点・辺情報の記号的表現」に限定して話を進める。
対象とする図形
- 対象は3面頂点図形とする。
つまりすべての面が平面(すべての辺が直線)であり、 各頂点には3つの面(したがってその境界として3本の辺)が集まる図形である。
参考: 3面頂点立体の例としては、一般の角柱(底面が n 角形(n≧3))、 三角錐などがある。
(底面が四角形以上の錐体は、頂点に4つ以上の面が集まるため、3面頂点にはならない。)
また3面頂点立体同士をつなげたり、3面頂点立体の一部から3面頂点立体を取り除いたものも 一般には3面頂点立体になる。
したがって3面頂点立体のバラエティはかなり大きいので、いろいろ試してみるとよい。- 辺へのラベリングは Huffman-Clowes 流の基本的なものに限定し、 Waltz による拡張で扱われているような影やクラック等は扱わない。
- 以下では扱う図形の説明とともに、 公開するプログラムでのデータ記述形式についても合わせて説明する。
ただし記述形式の詳細についてはデータファイルの記述形式参照。
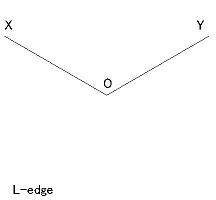
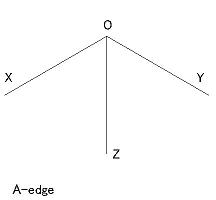
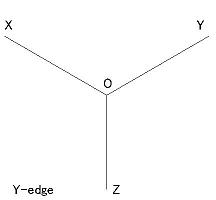
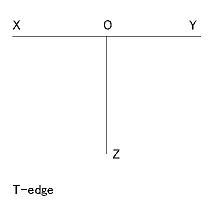
- 頂点の種類は下図のような4種類ある。 ただし、T 型は見かけの頂点である。
なお角の大きさそのものは、上記の制約以外には制限はない。 例えば L 型で、2辺が交わる角(図の XOY)が鋭角であってもよい。
- L 型: 1つの辺が隠されているもの(下図:角 XOY の間)
- A 型: 2辺間の最大角が 180°より大
- Y 型: 2辺間の最大角が 180°より小
- T 型: 2辺間の最大角が 180° (見かけの頂点:図の上側の面に下側の辺が隠されている)
|
|
頂点情報の書き方
- 頂点情報は、頂点の種類(L, A, Y, T のいずれか)、 頂点名(上図の O)、辺の接続先の頂点名(上図の X, Y, Z)を記す。
辺には固有の名称はつけず、「辺 OX」のように、両端の頂点名で参照する。- 接続先の頂点は、各辺を上図の配置に置いたときに、左から順(X, Z, Y の順)に指定する。
例えば L 型頂点で上に凸(上下が引っくり返った形)の場合、 図の X, Y は左右が逆になる。
この順番を間違えると正しい処理ができないので要注意!- 上図のそれぞれの頂点は下表のように記述する(記述方法については後の記述例も参照)。
注: L 型の「L O XY」は「L O X-Y」と書いてもよい:後述参照。
頂点 L 型 A 型 Y 型 T 型 記述方法 - 重要!!
T 型頂点につながる辺・頂点の場合、端点は T 型頂点のそれを書く。
例えば上図の T 型頂点につながる頂点 X について、 X から辺 XOY でつながる頂点は O であって Y ではないことに注意。
Y についても同様。
辺のラベル
- 辺には右図のように、4種類のラベルがつく(ただし、矢印2つは実質的には同じもの)。
1つの辺には1つのラベルがつき、同時に複数のラベルがつくことはない。- 以下では +、−のラベルは右図のように○で囲って表す。
- 矢印ラベルは、矢印の進行方向右側に図形の面(図)、 左側に背景(地)があることを表す。
したがって右図の2つの矢印の間に図が、外側に地があることになる。- +ラベル(凸ラベル)は両側とも図であり、 面がこちら側から見て出っ張っていることを表す。
- −ラベル(凹ラベル)は両側とも図であり、 面がこちら側から見てへこんでいることを表す。
- 線画の立体的な解釈が定まれば、各辺にはただ1つのラベルが確定する。
逆に言えば、各辺のラベルを確定するのが線画の解釈である。
可能なラベルの候補は、ラベル辞書 によって絞り込む。- ただし、図形自体が曖昧である(複数の解釈が可能である)場合には、
ラベルは唯一に確定できず、複数の候補が残る辺がある。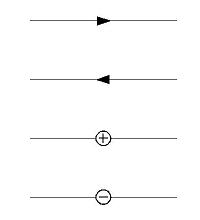
辺のラベル情報の書き方
- 頂点情報だけではラベリングは唯一に決まらない。
特に図形全体の外周(輪郭線)について、 地の面とつながっているのか浮いているのか(ラベルが「−」か矢印か)は 曖昧性として必ず残る。- そのようなつまらない曖昧性を排除するには、 特定の辺について、ラベルを明示的に指定すればよい。
(理想的には自動抽出したいが、それは当面の範囲外)
- 辺のラベル指定は以下の要領で行なう。 なお同じ辺に複数のラベルを指定した場合には、どちらも有効となる。
辺 AB について、A から B への(右向き)矢印ラベル。 「< BA」と同じ。 辺 AB について、B から A への(左向き)矢印ラベル。 「> BA」と同じ。 辺 AB は「+」ラベル。 「+ BA」でも同じ。 辺 AB は「−」ラベル。 「- BA」でも同じ。 「> AB; > CD」と同じ。つまり辺 AB, CD とも右向き矢印で、 複数の辺をまとめて書く書き方。 「> AB BC CD」と同じ。つまり辺 AB, BC, CD とも右向き矢印で、 輪郭線等をまとめて書く書き方。
- ここでは公開プログラムへの入力データ形式(原則としてファイルに格納)の詳細を述べる。
自分でプログラムを作成する場合にはこれにしたがう必要は必ずしもないが、
特に問題がなければ、共通形式にしておいたほうが何かと便利ではあろう。
- 頂点
- 頂点には半角文字(ASCII 文字)1文字の名前をつける。 原則として、アルファベット(大文字・小文字)、数字の計 62 文字を用いる。
(正確には、ASCII の印字文字 94 字のうち、 以下で述べる特殊用途の文字(% ; -)を除いたものはすべて使えるが、 必要がない限りは英数字を推奨する。)- 頂点名は、上記の文字のうちから自由に用いてよい。
例えばアルファベット順に連続して用いたりする必要はない。- 大文字・小文字は異なる頂点として扱う(例えば A と a とは別の頂点である)。
- 頂点の種別定義に用いる L, A, Y, T も頂点名として自由に使ってよい。
ラベル定義の >, <, +, - についても同様。
- 文
- データを定義する「文」には「頂点定義」と「辺ラベル定義」の2種類がある。
いずれも前節「頂点の種類・書き方」で述べたものである。
- 頂点定義
形式: [頂点の種類] [頂点名] [接続頂点][頂点の種類] は L, A, Y, T のいずれか (大文字でなければならない)。
[頂点名] は頂点につけた名前、 [接続頂点] は頂点につながる辺を、もう一端の頂点名で表したもの。
接続頂点の記述順については上記参照。
接続頂点数は、L 型の場合は 2、他の A, Y, T 型の場合は 3 である。
ただし、他と形式を合わせるため、L 型については「L A BC」の他に、 間に - を挟んで「L A B-C」と書いてもよい ('-' が隠された辺に対応すると思えばよい)。
- 辺ラベル定義
形式: [ラベルの種類] [辺情報][ラベルの種類] は >, <, +, - のいずれか。
[辺情報] は、ラベルをつける辺を、両端の頂点名を書いて示す。
「AB CD EF」のように複数の辺を書いたり、 「ABCDA」のように辺の連鎖として書いてもよい (これは「AB BC CD DA」と同義)。
複数の辺を指定する場合には間に空白を入れる。 逆に辺となる2頂点名の間に空白をいれてはならない。
- 頂点定義の順番は自由である(アルファベット順、ASCII 順であったりする必要はない)。
同様に辺ラベルの定義順も自由である。- 辺ラベル定義文は、頂点定義文より後におかなければならない。
正確に言えば、頂点定義文ですでに定義された頂点でなければ、 辺ラベル定義文中で用いることができない。
余計な混乱を避けるためには、頂点定義を最初にまとめておき、 辺ラベル定義はすべてその下に置くようにすればよい。- 同じ辺に複数のラベルを定義した場合にはそのすべてが可能なラベルになる。
例えば「> AB; < AB」とすれば、 辺 AB のラベルは >, < のいずれかになる。
- コメント
- データの行中に %(パーセント)の文字があると、 以後その行の末尾までをコメントとして読み飛ばす。
行の先頭に % がある場合にはその行全部がコメントになる。- コメント中では全角文字(日本語コード)を用いてもよい。
コメント以外のデータ部分では全角文字は書かないこと(全角空白も含む)。- コメントはデータの説明(データが大きい場合には重要!)や、 データの一部を一時的にアクセスできないようにするなどの目的に用いるとよい。
- 空白・改行の扱い、文の区切り
- 本記述形式ではスペース文字(空白、タブ、改行)の扱いは緩やかで、 混乱の恐れがなければ自由に挿入・削除してよい。
例えば「L A BCD」は 「L A B C D」、 「LABCD」などと書いてもかまわない。 もっともわかりやすさを考えれば、最初のものが適切だろう。
同様に、「< AB」を「<AB」と書いてもかまわない。- ただし、辺ラベル定義の辺情報は例外で、 辺でつながれる頂点間はスペースなし、 そうでなければスペースを入れなければならない。
すでに見たように、「+ ABCD」と「+ AB CD」は別物で、 前者は辺 BC に + ラベルがつくが、後者ではつかない。- 1行に複数の文を入れる場合には、 文の末尾に ;(セミコロン)をつける (上のいくつかの例でも用いている)。
行の末尾の文にはセミコロンをつける必要はない(つけてもかまわないが)。
- データ中でのファイルの読み込み
(未実装)
- 辺のラベルは4種類あるから、単純計算では、辺が2本の頂点(L 型)には 42 = 16 通り、3本の頂点(A, Y, T 型)には 43 = 64 通りのラベリングができる。
しかし実際に3面頂点図形に現れるラベリングはそのうちの一部にすぎない。 それを下の表(ラベル辞書)に示す。
(このラベル辞書をどう導くかについてはここでは扱わない。)
- 線画の解釈とは、実質的には各頂点に辞書項目のいずれか1つを割り当てる処理であり、 その際「制約」として働くのが次の2点である。
- 各辺にはただ1つのラベルがつく(辺は両端で頂点につながっていることに注意)。
- 頂点につながる辺のラベルは、辞書項目の1つと完全に一致する。
- 辞書中の各項目には L1〜L6、A1〜A3、Y1〜Y5、T1〜T4 の名称がつけてあり、 プログラム中でもその名称によって参照する。
- 各項目の図をクリックすると拡大画像が表示される。
- Y2〜Y4 は回転すれば同じラベリングだが、 プログラムでは頂点の位置(左・下・右)を固定して扱うため、 別々の辞書項目となっている。
| L 型頂点(6 個) L1〜L6 |
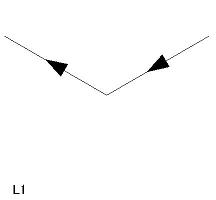
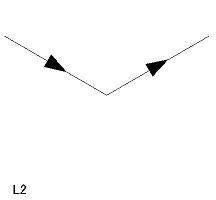
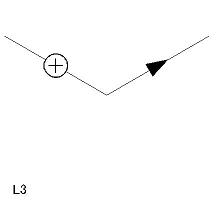
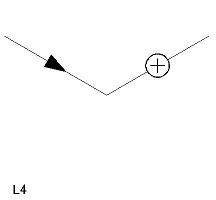
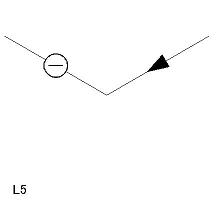
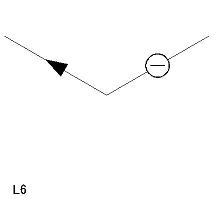
|
| A 型頂点(3 個) A1〜A3 |
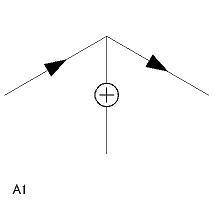
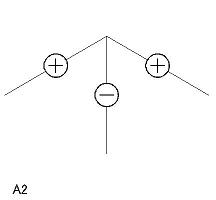
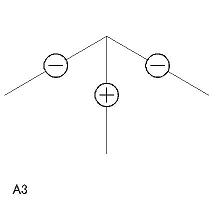
|
| Y 型頂点(5 個) Y1〜Y5 |
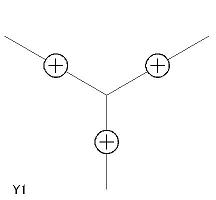
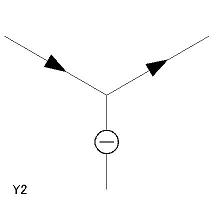
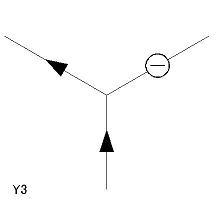
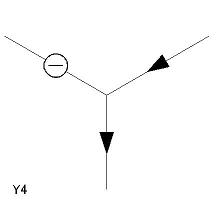
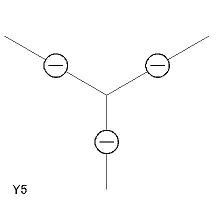
|
| T 型頂点(4 個) T1〜T4 |
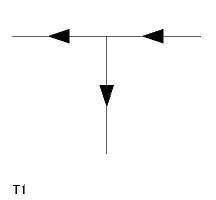
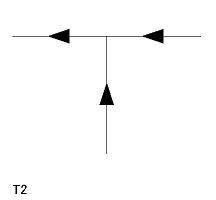
|
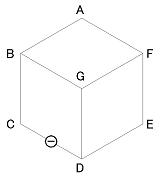
- 以下にはデータ記述の簡単な具体例を示す。 題材は図に見られるような立方体の線画である。
- スペース節約のため、1行に複数の文を書いているが、 見易さの観点からは別々の行にしたほうがいいかもしれない。
- (1) は頂点定義だけを与えた例、(2)〜(5) は頂点定義は同じで、 辺ラベル定義を加えた例である。
(6) は側面に穴が開いている例である。
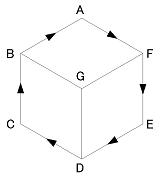
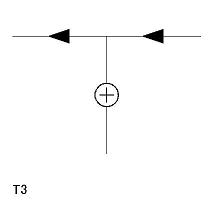
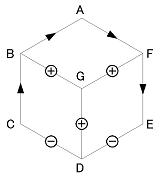
(1) 頂点ラベルだけを記述L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDFこの場合、解釈は1通りには絞られず、下の4つのラベリングが可能である。
2〜4番目は回転すれば同じもので、輪郭線のラベリングの問題である。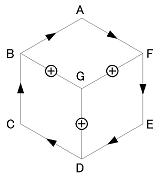
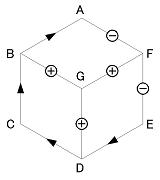
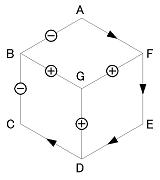
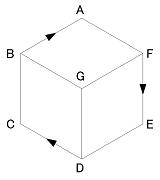
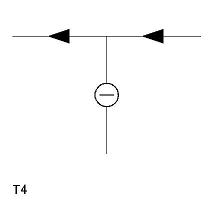
(2) 輪郭線のラベルをすべて指定L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDF > AFEDCBAこの場合、解釈は上の最初の1つに決まる。
ただし、一意に絞るには全部の輪郭線を指定する必要はない。
(3) 輪郭線の一部ラベルを指定 (1)L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDF < AB CD EFこのように一部(3辺)だけでも解釈は一意に決まる。
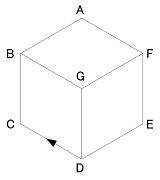
(4) 輪郭線の一部ラベルを指定 (2)L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDF < CDこのように1辺だけの指定では一意に決まらない(いくつ可能か?)。
(5) 輪郭部に凹ラベルを指定L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDF - CD輪郭部に凹(-)ラベルを指定した例。
この場合、解釈はいくつあるか?
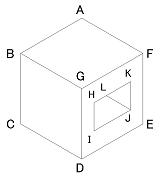
(6) 側面に穴の開いた立方体L A F-B; L C B-D; L E D-F; A B CGA; A D EGC; A F AGE; Y G BDF; L H L-I; L I H-J; A J KLI; L K J-L; T L HJK;面 GDEF の中に穴が開いている例。
HIJK が穴、L は T 型頂点で、辺 LJ が辺 HK で隠された見かけの頂点である。
上の頂点定義にもあるように、辺 HK は L を挟んで HL と LK に分割して定義すること。
図からもわかるように、立方体本体(頂点 A-G)と穴(頂点 H-L)とは互いにつながりがない。
これを A-G、H-L はそれぞれ別の グループ に属していると呼ぶ。
異なるグループ間ではラベリングは互いに独立で、相互に影響しない。
上の頂点定義では HIJK が面 GDEF の穴であることは何も規定されていない点に注意。
穴が面 ABGF, BCDG にあったとしても頂点定義は同じで、相互に区別はつかない。
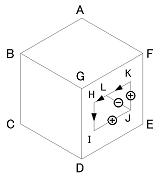
今の場合、穴のラベリングは唯一に決まる。それを右図に示す。
- 上述のように、頂点に集まる辺のラベルは、ラベル辞書によって制約を受ける。
(例えば T 型頂点の横線2本のラベルは、左向き矢印の1通りしかない。)
また各辺につくラベルはただ1つでなければならず、 これによって両端の頂点における辞書項目も制約される。- これらの制約の相互作用によって、辞書項目や辺ラベルの候補を絞り込んでいくことがきでる。
例えば辺 AB において、
・頂点 A における辞書項目からは > + - の3つのラベル
・頂点 B における辞書項目からは < + - の3つのラベル
が可能としよう。 すると AB では両者の共通要素である + - の2つのラベルだけが可能となる。
これにより、頂点 A では AB を > とする辞書項目が、 B では < とする辞書項目が候補からはずれることになる。
それがさらに頂点 A, B の他の辺でのラベルを制約することになり、 可能な候補がさらに絞られていく。
- このように局所的な制約(今の場合、個々の辞書項目・辺についての制約) が全体に広がっていくことで
候補が絞り込まれることを、一般に「制約伝播 (Constraint Propagation)」と言う。
(「制約伝搬」とも書く。Waltz の用語では Relaxation method(緩和法))
また制約の伝播により問題を解決する方法(アルゴリズム)を「制約伝播法」と言う。制約伝播法のアルゴリズム
- 上記に基づいて、制約を伝播していくことで可能なラベル・辞書項目を絞っていく。 具体的には以下の通り:
- 初期設定では、各頂点では該当する型のすべての辞書項目を、 各辺ではすべてのラベルを候補とする。
- 各辺のラベル候補のうち、両端の頂点の辞書項目候補にないラベルを削除する。
- 各頂点の辞書項目候補のうち、いずれかの辺にラベル候補がない項目を削除する。
- 上の 2, 3 を繰り返す。
その過程で、辞書項目候補が 0 になってしまった頂点、 ラベル候補が 0 になってしまった辺があれば、
「ラベリング不可能な図形」として終了する。- 2, 3 のステップによって削除される候補が1つもない場合には終了する。
- 5 の結果、すべての辺のラベル候補が1つに絞られたなら、それが解となる。
- 一方、複数の候補が残っている場合には、次のいずれかにあたる。
第1点の場合、制約伝播そのものでは複数解を列挙するのは困難である(後述)。
- 解そのものが複数個ある、つまり問題が曖昧である。
- 単独の頂点ごと、辺ごとの制約しか見ていないため、 もっと広い範囲で見れば絞れる候補が絞りきれていない。
第2点は次のような例で考えてみよう。このように、いくつかの頂点の集合や辺の集合をひとまとまりとして、 それを単位として制約を考えていけば、可能な候補は一般に絞り込める。
- A は Y 型頂点、B は A 型頂点で、辺 AB は A の下辺、B の下辺であるとする。
- このとき AB に可能なラベルは +, - の2種類であり、
A については Y1, Y2, Y5 が、B については A1, A2, A3 が可能な辞書候補となる。- しかしこのすべての組み合わせ(3×3 = 9 通り)が可能なわけではない。
実際に可能なのは、+ ラベルに対応して {Y1, A1}, {Y1, A3} の2つ、 - ラベルに対応して {Y2, A2}, {Y5, A2} の2つの 合計4通りだけである。- この4通りに限定すれば、A, B から出る他の辺の組み合わせに対する制約となり、 可能な候補が絞り込める可能性がある。
極端な話、全部の頂点、全部の辺をひとまとまりに扱ってしまえば、 制約を適用した結果がそのまま問題の解になる。
(もちろんこれはナンセンスな話であって、 「制約を適用する」こと自体を極端に複雑化しているにすぎない。)- 上の第1点、第2点の見極めと考察が、レポート作成上の重要なポイントになる。
探索(仮定法)との比較
- 制約伝播法の1つの対極にあるのが普通の探索である。
- 制約伝播法は局所的な制約を全体として徐々に絞っていく方法であるのに対し、
探索は局所的な部分ごとに可能性を絞ってしまい、 それが全体に通用するかを調べに行く方法である。- 今の場合、各辺・頂点でのラベル候補・辞書項目候補について、
制約伝播では連結する頂点・辺同士の制約から候補を順々に絞っていくのに対し、
探索では候補の中から特定の1つを選び、それを繰り返して:を調べる。
- 解に至るか(矛盾のない候補の割当てができるか)、
- 矛盾が生じるか(候補の割当てができなくなるか)
ある候補を仮定して矛盾が生じないかを調べていくという意味で、 「仮定法」と呼ぶこともできる。- 解が1つあればいいなら、解が見つかった時点で終了すればいいのに対し、
全探索では解が見つかっても探索を続行し、すべての場合を尽くす。
- 探索の最大の問題点は、各ステップで可能な候補を特定してしまう点にある。
このため、早い段階で仮定された候補が実際には不適なものであると、 以後の探索はすべてムダになる。
また探索木の同じ部分木をなんども探索し直すといったムダも生じうる。- これに対し、制約伝播は「ありえないケース」から順に除外していくという処理であるため、
そのような意味でのムダは避けられる。- また「ある候補を仮定して先に進み、矛盾が生じないかを調べる」という探索による解法は、
人間にとっては実行しにくく、心理的にも避けようとする傾向が強い。
制約伝播のほうが、人間が行なう解法に近く、なじみやすい。
これはパズルなどの解き方を考えても同じである。
人間の解き方は制約伝播法に近く、探索法(仮定法)は「最後の手段」の感がある。
(このあたりに立ち入った考察がなされることが望まれる。)
- 反面、制約伝播は可能な候補を絞っていくアプローチのため、 状態数が多かったりすると、初期状態では候補が膨大な数になりうる。
しかもその大部分は制約伝播の初期段階で消えてしまい、 生成するだけムダといったことになりかねない。- また上記のように、制約の伝播範囲が狭いと、たとえ解が1つに決まるような場合でも 伝播プロセスが途中で行き詰ってしまうこともある。
伝播範囲を広げるようにプログラムを改造するのは、一般にはかなり難しい。- これに対し、探索法のプログラムはもっと簡単でコンパクトであり、
実行時間を気にしなければ、解が存在すれば必ず見つかるというのが大きな利点である。- したがって両者の利点を生かした併用・融合型の処理を考えることも価値がある。
(本プログラムの「制約後探索」モードは、その最も原始的な形。)
- 公開プログラムの使い方としては次の2通りがある: どちらもプログラムとしての動作・出力結果は同じである。 (というか、実際には同じプログラムが動く。)
- 以下にはどちらの使い方にも共通な事項について記す。
プログラムの概要
- プログラムは制約伝播モードと探索モードの2つの実行モードがある。
実行モードは実行時オプションで指定する (制約伝播のみ、制約伝播後に探索、探索のみのいずれか)。- 制約伝播モードでは頂点(の辞書項目)、辺のラベル間の単純制約伝播を行う。
- 探索モードでは頂点の辞書項目について、深さ優先の単純全探索を行う。
これにより、可能な解がすべて列挙される。 探索及び解の列挙は、グループ単位 で行われる。
(探索プログラムはかなり改良の余地がある。)
- プログラムはデータ(頂点定義・辺ラベル定義)を入力し、上記の実行結果を出力する。
入力データや中間経過などもオプションに応じて出力する。
- プログラム全体は約 1000 行だが、中核となる処理は制約伝播・探索を合わせても 100 行程度である。
- それ以外の部分は、初期設定、データや結果の入出力、実行状況のモニタリングなどからなる。
- 入力データのエラー解析は万全とは言えないので、 エラーが生じた場合には入力データそのものをよく見直すこと。
制約伝播モード
- 初期状態としては、各頂点においてはすべての辞書項目、 各辺においてはすべてのラベルを候補として登録する。
- 各ステップでは、以下の2種類の制約伝播をこの順に実行する。
伝播によって候補が減らなければ終了する。 そうでなければ上のステップを繰り返す。
- 辺(ラベル)に対する制約伝播
- 頂点(辞書項目)に対する制約伝播
- 辺への伝播では、辺のラベル候補のうち、両端の頂点の辞書項目にないものを削除する。
- 頂点への伝播では、頂点の辞書項目候補のうち、 辺のラベルがその辺のラベル候補にないものを削除する。
- 最終結果は「頂点モード」で表示される。
またオプションで指定した場合には、各ステップごとに、 辺への制約伝播後に 辺モード、 頂点への制約伝播後に 頂点モード の出力を行う。- 終了時に各辺のラベルがただ1つずつに決まれば、それが唯一の解を与える。
複数の候補が残る場合には、前述のように、そもそも解が複数あるか、
解の個数に関わらず制約が不十分にしか働いていないのかのいずれかである。
一方、候補が1つもなくなってしまった場合にはラベリング不可能図形である。- 解が唯一に確定した場合、あるいはラベリング不可能な場合には実行を終了する。
複数候補が残り、実行モードが「制約後探索」の場合には探索モードに移る。探索モード
- 頂点の辞書項目について、深さ優先の単純全探索を行う。
探索は グループ単位 で行う。- 実行モードが「探索のみ」の場合には初期状態から、 「制約後探索」の場合には制約伝播が終了した状態から探索を行う。
- 探索は1番目の頂点の辞書項目候補のうちから1つを選び、 それによって辺ラベルを確定し、2番目以降の頂点の探索に移る。
その探索が終了したら、2番目以降の候補についても同様の探索を行う。
- 探索にあたり、すでに確定した辺ラベルと矛盾するラベルを割り当てる候補は 探索対象から除外される。
候補が1つもない頂点に達した場合には探索は失敗し、バックトラックする。- すべての頂点への候補割当てが成功すれば、解が1つ見つかったことになるので、結果を出力する。
- プログラムは頂点の定義順に、機械的に探索を行うので、 頂点の定義順を変えると探索回数が大きく変わる可能性がある。
(解の探索結果には影響しない。)出力形式
- 出力は頂点ごとに行われ、「頂点モード」と「辺モード」の2種類がある。
両者は見かけは似ているが、表す内容は異なっている。- 頂点モード出力は、各頂点に候補として残っている辞書項目を列挙する。
- 一方、辺モード出力は、各辺に候補として残っているラベルを列挙する。
- 辺のラベルは以下の記号で表す。
右向き矢印(→) 左向き矢印(←) +ラベル(凸ラベル) −ラベル(凹ラベル)
- 出力は、左端に注目している頂点名、続いて頂点の型、 そして辺のラベルを示す。
辺ラベルは、注目している頂点を中心として左右の辺のラベルを示し、 L 型頂点以外では、第3の辺(下辺)のラベルをその後に示す。
以下は具体例。
頂点
モード頂点 B の辞書項目が A1 で、CB, BA は→ラベル、BD は+ラベルを表す。
辞書項目が1つしかないので、B は A1 に確定である。
L5 F -(-)- G --<-- X頂点 G は L 型頂点で、L1, L5 の2つの候補がある。
FG は←ないし−ラベル、XG はどちらの場合も←ラベルで、
これにより XG が確定する。
辺
モードB は A 型頂点で、各辺には候補が1つずつしかない。
したがって B の辞書項目も一意に確定する(A1 になる)。
-(+)-
-(-)-A は D, B を結ぶ L 型頂点で、AB のラベルは ← のみ可能だが、
DA には ←、+、− の3種類が可能である。
-(+)- -(+)- -->--
-(-)- -(-)-L は M, P, O を結ぶ A 型頂点で、ML, LO はそれぞれ3種類、
LP は2種類のラベルが可能。
ラベルの縦並びの順番や、横並びに何が並ぶかには意味がない。その他 *** 不可能(残り候補なし) *** この頂点はラベリング不可能であることを表す。
- 制約伝播モードで、見出し部に「確定」とあるのは、 その時点までに確定した(候補が1つになった)
頂点の数(頂点モード)あるいは辺の数(辺モード)。
同様に「未確定」は未確定(候補が複数)であるものの数、 「不可能」は候補が 0 になったものの数。
- 探索モードで解が見つかると、結果を頂点モードで出力する。
- また中間結果は下のように表示される。
左端の数字は探索の再帰呼び出しが行われた回数を表す。
それ以下は、仮定した頂点の辞書項目が表示される。 字下げ(インデント)は探索の深さを表す。
上の例は、探索の最初の4回の再帰呼び出しまでのもので、頂点 A について L1 を仮定し、
続いて B は A1、C は L1、D は A1 を仮定していって探索していることを表している。グループ
- 相互につながった頂点の集合を グループ と呼ぶ。
正確には、頂点 X, Y が同じグループに属するとは、 X から辺をたどって Y に行き着く経路があることを言う。
逆に X から Y に行き着く経路がなければ、X と Y は異なるグループに属する。- 例えば上の 穴つき立方体 の例では、 頂点 ABCDEFG からなるグループと、HIJKL からなるグループの2つがある。
- 異なるグループ間のラベリングは相互に独立であり、 一方の結果が他方に影響を及ぼすことはない。
したがってラベリングはグループ単位で扱うのが自然である。
- 制約伝播モードでは、辺でつながっている頂点間にしか伝播が及ばないから、 自然にグループ別の処理になる。
- 探索はグループごとに別々に行い、解もグループごとの解として示す。
これは組み合わせ的爆発を避け、探索プロセスの効率化や解の出力を圧縮するためである。
例えばグループが3個あり、各グループの解の個数が 2, 3, 4 であったとしよう。
グループごとの探索であれば出力される解の個数は 2+3+4 = 9 個であるのに対し、
グループを区別しない全体探索だと、そのすべての組み合わせである 2×3×4 = 24 個の解が出力されてしまう。
それに応じて、探索ステップ数も爆発的に増えることになる。
ただ解がグループ別に表示されるため、 全体としてどのような解になるかはそれらを手で寄せ集めてみる必要がある。
- 下左図は少し複雑な情景の線画である。
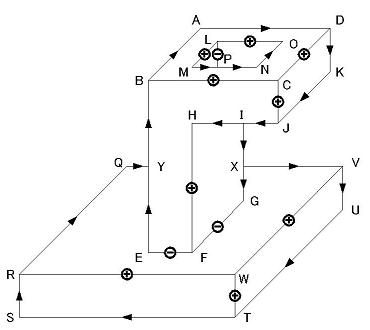
頂点定義ファイルは data2.txt にあるが、 練習として自分で記述できるかを試してみること。- 頂点定義だけでは解は一意に決まらない(いくつあるか?)。 下右図は解の1つである。
複数解がある場合、辺ラベル定義によって解を絞り込むことができる。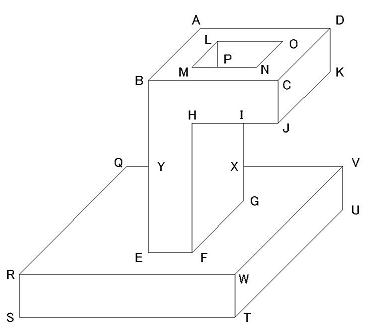
レポート課題としては以下のような点がレポート作成・考察のポイントになるので、 よく留意すること。(以下考察のポイント)
- 実行例は処理の特徴が十分反映されるような、バラエティのある例を用意する。
- 出力は説明に必要な範囲に限定し、不要な出力は極力抑制する。
- 制約伝播と探索など、他の方法との全般的な比較。
さらに、最初から探索のみを実行する場合と、制約伝播後に探索を起動することとの比較。- 制約伝播で複数の候補が残る場合、制約伝播の能力不足のためか、 解そのものが複数あるためなのかの考察。
とりわけ、前者の具体例(探索の結果、解が一意に決まることがその目安になる)。- 解が複数生じる原因の1つは、面と背景、あるいは面同士が 接しているか離れているかの曖昧性にある。
(記述の例 における立方体の4つの解も参照。)
これ以外の理由で、線画が本質的に曖昧であるような例があるかを検討し、 あるならそれを示す。- 人間が手でラベリングを行なう場合との比較。
人間はプログラムと同じような処理を行なうか? そうでなければどのような処理を行なっていると考えられるか?
- ラベリング以外の問題で、制約伝播が有効であるような例とその理由(パズル等)。